What Is Reinforcement Learning Explained

If you’ve ever tried to teach a dog a new trick, you already have a gut feeling for what reinforcement learning (RL) is all about. You don’t hand the dog an instruction manual. Instead, you reward it with a treat for good behavior, helping it figure out which actions get the best results.
This is exactly how RL teaches machines to master complex tasks. An AI agent learns what to do—and what not to do—by interacting with an environment and trying to get the most rewards it can over time.
How Do Machines Actually Learn From Experience?
At its core, reinforcement learning is all about learning from consequences. It’s a huge departure from other machine learning methods that need a ton of pre-labeled data to get started. An RL agent is just dropped into a situation and has to figure out a winning strategy, or “policy,” based purely on feedback.
This feedback is simple: rewards for doing something right (positive feedback) and penalties for doing something wrong (negative feedback).
This is a fundamental shift from how we traditionally build software. Instead of writing out explicit, step-by-step rules for every possible scenario, we design a system where an AI can discover the best moves on its own. It’s a concept that many leading AI experts — like our roster speaker Allie Miller, one of the world’s foremost voices in machine learning and AI strategy — point to as a key ingredient for building truly smart, autonomous systems.
The goal isn’t just to complete a task, but for the machine to learn the best possible way to complete it. To see where this fits in the bigger picture, check out our guide on the key differences between deep learning vs machine learning.
Reinforcement learning is a trial-and-error method for a machine to learn a new skill. The process involves an agent, a reward, and an environment, with the goal being to maximize the reward. This all boils down to a continuous loop:
- The agent observes its environment.
- It takes an action.
- It receives a reward or a penalty.
- It updates its strategy based on that outcome.
The Core Components of a RL System
To really get what reinforcement learning is all about, you first need to meet the key players. Every single RL system, no matter how complex, is built from the same handful of fundamental parts. These components work together in a constant feedback loop, which is exactly how an AI learns from its own trial and error.
Think about a self-driving car figuring out how to navigate a chaotic city intersection. This car is our agent—the learner and decision-maker. It’s the piece of the system we’re trying to teach a new skill. The world it has to deal with, from the roads and traffic lights to other cars and pedestrians, is the environment.
The agent interacts with its world by taking actions. For our car, an action could be turning left, hitting the gas, or slamming on the brakes. Each action changes things, leading to a new state. A state is just a snapshot of the agent's current situation, like its GPS coordinates, speed, and proximity to other cars.
And here’s the most important part: after each action, the environment gives the agent some feedback as a reward or a penalty. Getting closer to its destination might earn it a positive reward, while a wrong turn or a near-collision would definitely result in a penalty. This feedback is what guides the agent toward its ultimate goal.
The Learning Loop Visualized
This infographic perfectly captures the cyclical relationship between the agent, its actions, the environment it's in, and the rewards it gets back.
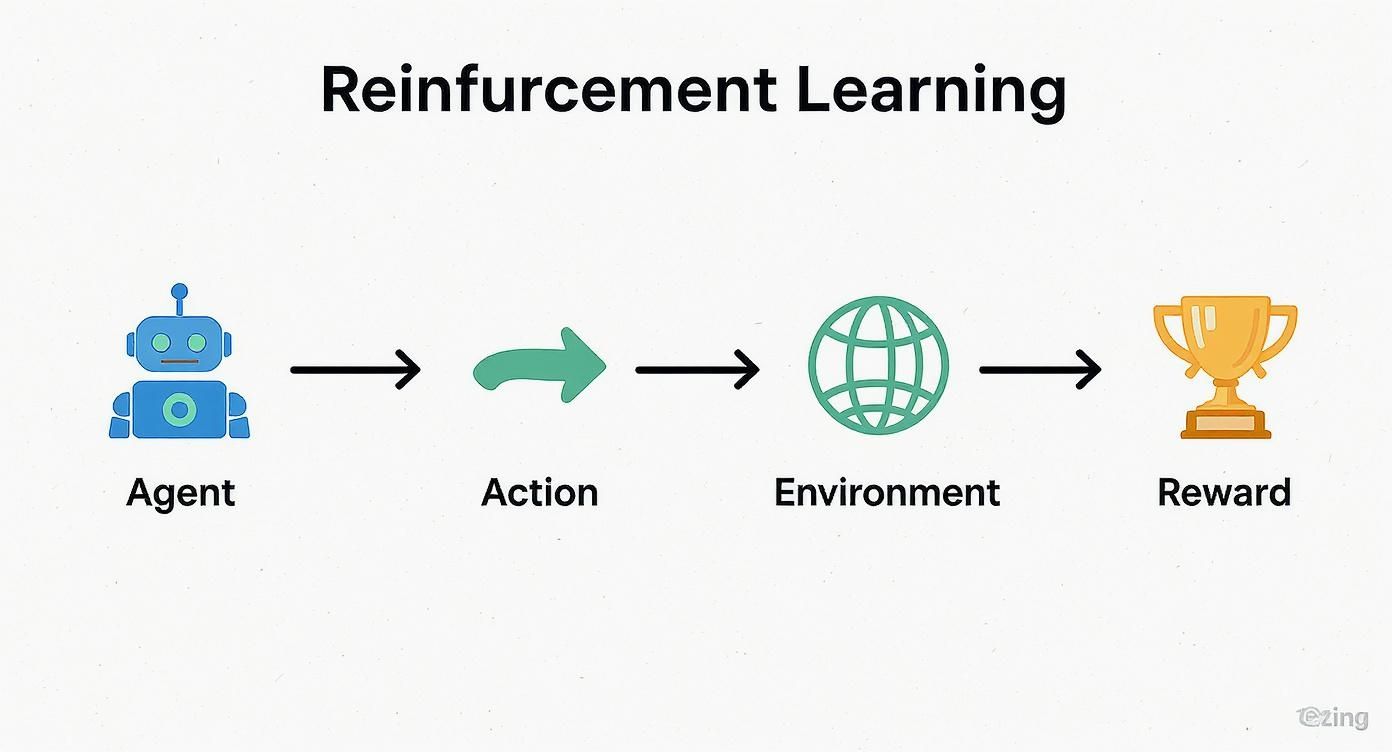
As you can see, this isn't a one-and-done process. It’s a continuous loop where each part directly influences the next, pushing the learning process forward one step at a time.
At its heart, reinforcement learning is about an agent figuring out the best actions to take in various states to maximize its cumulative reward over time. It’s a dynamic puzzle where the agent learns the rules of the game as it plays.
To put these concepts into a simple framework, here’s a quick breakdown using a more familiar analogy: training a dog.
Key Reinforcement Learning Concepts Explained
| Component | Role | Simple Analogy (Training a Dog) |
|---|---|---|
| Agent | The learner or decision-maker. | The dog you are training. |
| Environment | The world the agent operates in. | Your house, the backyard, and you (the trainer). |
| Action | A move the agent makes. | The dog chooses to sit, stay, or bark. |
| State | The agent's current situation. | The dog is in the living room, and you just said "sit." |
| Reward | Feedback from the environment. | Getting a treat for sitting (positive) or a firm "no" for barking (negative). |
Getting these basics down is non-negotiable. Once you understand this core loop—agent, action, environment, reward—you’re ready to see how RL models are used to solve incredibly complex problems, from mastering robotics to navigating financial markets. These components are the universal language of reinforcement learning.
How an RL Model Learns and Makes Decisions
So how does an RL agent actually get smart? It starts out by making completely random guesses, stumbling around its environment with no real clue what to do. But it doesn't stay clueless for long.
The magic happens inside the model’s “brain,” which is powered by two key components: the Policy and the Value Function.
Think of the Policy as the agent's playbook. It’s a set of rules—a strategy—that dictates what action to take in any given situation. At first, this playbook is pretty much empty. But with every reward or penalty it receives, the agent scribbles in new notes, slowly figuring out which moves lead to a win.
The Value Function, on the other hand, is all about foresight. It helps the agent predict the long-term rewards it can expect from being in a particular state. This is like a chess master who isn't just thinking about their next move, but is already picturing the board five moves from now. This long-term vision guides the agent toward actions that set it up for future success.

The Exploration vs. Exploitation Dilemma
To truly master its environment, every RL agent has to walk a tightrope. This is the classic trade-off between exploration (trying new things to see what happens) and exploitation (sticking with what it already knows works).
If an agent only exploits, it might get stuck in a comfortable routine, repeating a decent strategy but never discovering a brilliant one. It found a good move, but not the best move.
But if it only explores, it becomes a wanderer, constantly trying new things without ever capitalizing on what it's learned.
The key is balance. The agent has to explore enough to find the best possible strategies, but also exploit that knowledge to actually rack up rewards.
This constant push and pull with its environment is fundamental to how RL operates. It's a lot like the principles of discovery-based learning for humans, where we learn best by doing and experimenting, not just by being told what to do. It’s this dynamic process that makes RL so incredibly powerful for tackling messy, real-world problems.
Exploring Popular Reinforcement Learning Algorithms
Now that we have the core concepts down, let's look under the hood at the engines that power an agent's learning. Reinforcement learning algorithms are the mathematical frameworks that turn raw experience into a winning strategy. They mostly fall into two main camps.
First, you have value-based methods. A classic example here is Q-learning. Think of Q-learning as building a massive cheat sheet, called a Q-table, that maps out the future reward for taking any action from any state. After every single move, the agent updates this table, slowly but surely figuring out which actions are goldmines and which are dead ends.
Policy-Based and Hybrid Methods
On the other side are policy-based methods, which cut straight to the chase. Instead of calculating the value of every possible move, these algorithms learn the policy itself—the agent's actual decision-making strategy. The model directly tweaks the probability of choosing certain actions, aiming to maximize its rewards over the long haul. This approach is a lifesaver in complex environments where creating a value table for every state would be completely impractical.
Eventually, these two approaches were combined, leading to a huge milestone in AI: Deep Reinforcement Learning (DRL). This hybrid method pairs the trial-and-error learning of RL with the incredible pattern-recognition skills of deep neural networks. This allows agents to learn directly from messy, high-dimensional data, like the raw pixels on a screen.
The development of DRL was a turning point. It allowed models to learn complex behaviors directly from sensory data, much like a human, without needing manually programmed features.
This was put on full display back in 2015 when Google DeepMind's Deep Q-Network (DQN) taught itself to play old-school Atari games just by looking at the screen. The DQN achieved superhuman performance in 49 of 57 games, scoring 74% higher than a professional human tester. This proved a single algorithm could master a huge range of different tasks—a massive leap forward for artificial intelligence. You can see where this fits on a broader timeline of deep learning.
Real-World Applications of Reinforcement Learning
Reinforcement learning isn't just an academic exercise—it's actively changing how entire industries operate. From the factory floor to the stock market, RL agents are tackling complex, dynamic problems that once seemed to require a human touch. The core principles of RL are being put to work to solve some of the biggest challenges businesses face today.
You'll often see these applications highlighted by leading AI speakers like Tom Gruber, co-creator of Siri, who are on the front lines translating these powerful concepts into practical business results. They're showing the world that RL is the engine running behind the scenes of many systems we interact with every single day.

From Robots to Recommendation Engines
One of the most visible examples is in robotics. Instead of being hard-coded for a single, repetitive motion, industrial robots can now use RL to learn tricky tasks like assembly or quality control. They figure it out through trial and error, adapting to slight changes in their environment without needing a programmer to step in for every little variation.
In a similar way, the recommendation engines on platforms like YouTube and Netflix are powered by reinforcement learning. These systems don't just categorize content; they learn your personal tastes by watching what you do. Every time you watch, skip, or like a video, you're providing feedback that rewards the algorithm for getting it right, keeping you engaged.
Reinforcement learning has become a powerhouse in modern artificial intelligence, and the market reflects that. The global RL market was valued at $1.1 billion in 2021 and is on track to hit an incredible $10.6 billion by 2026—that’s a growth rate of 57.3%.
Beyond the factory and your screen, RL is also making huge waves in other critical areas:
- Autonomous Vehicles: Training cars to navigate unpredictable traffic by rewarding them for making safe and efficient driving decisions.
- Finance: Driving algorithmic trading systems that learn the best times to buy and sell based on real-time market data.
- Healthcare: Helping design personalized treatment plans that can adapt based on how a patient responds over time.
Putting these kinds of advanced systems into place requires a solid game plan. If your business is looking to get started, our guide on how to implement AI offers a clear roadmap. And when it comes to the nuts and bolts of getting the work done, understanding the different models for managing and outsourcing AI/ML development is key to making your project a success.
To really get what reinforcement learning is all about, it helps to know where it came from. The core ideas aren’t brand new—they’re a fascinating mash-up of computer science, control theory, and even animal psychology. This mix is exactly why RL has become such a powerhouse.
The mathematical heavy lifting started way back in the 1950s. While RL’s spirit comes from simple trial-and-error, its modern computational shape really started forming in the 1980s. A huge piece of the puzzle came from Richard Bellman’s work on dynamic programming, which gave us the math to tackle complex decision-making problems. If you're a history buff, you can explore the history of RL's core concepts and see how deep the roots go.
The Rise of Modern RL
Jump to the 1990s, and you'll see these theories explode into practice. The big breakthrough was temporal-difference (TD) learning, a method that let agents learn on the fly without waiting for a final outcome. This was a massive step toward making RL work in the real world.
This innovation led straight to TD-Gammon, a backgammon program that blew everyone's mind by playing at a world-class level against human pros. The amazing part? It wasn't taught by experts. It learned by playing against itself millions of times, discovering strategies no human had ever thought of.
TD-Gammon was a landmark achievement. It demonstrated that a machine could learn a complex strategy game through self-play and feedback, surpassing the knowledge programmed by its creators.
This journey shows that modern RL didn't just appear overnight. It was built layer by layer, with decades of research from different fields all coming together. Understanding this evolution is key to grasping why what is reinforcement learning has become such a critical question in AI today.
Got Questions About Reinforcement Learning?
Diving into reinforcement learning can bring up a lot of questions. Let's tackle some of the most common ones you might be thinking about.
Is RL Just Another Name for Supervised Learning?
Not at all. While both are types of machine learning, they learn in fundamentally different ways.
Think of supervised learning like studying with flashcards. You're given a massive deck of photos (the data) where each one is already labeled "cat" or "not a cat" (the correct answers). The goal is to get good at labeling new, unseen photos correctly. It learns from a pre-defined answer key.
Reinforcement learning, on the other hand, is like teaching a dog a new trick. There are no flashcards. Instead, the dog tries different actions (sits, rolls over, barks) and gets a treat (a reward) when it does the right thing. Over time, it learns the sequence of actions that leads to the most treats. RL learns from the consequences of its actions, not from a static answer key.
Is Reinforcement Learning and AI the Same Thing?
It's a common mix-up, but no. Think of it like this: Artificial Intelligence (AI) is the entire, vast field of building smart machines. Machine Learning (ML) is a major branch within AI that focuses on systems that learn from data.
Reinforcement learning is then a specialized, powerful technique within machine learning. So, RL is a type of AI, but AI is a much broader category that includes many other things, like natural language processing, computer vision, and expert systems.
What Makes RL So Difficult in the Real World?
While the concept sounds simple, putting RL into practice comes with some serious hurdles.
The biggest challenges usually boil down to three things:
- It needs a ton of data. An RL agent has to explore a massive number of possibilities to figure out what works. This can take millions or even billions of trial-and-error attempts, which is often too slow or expensive for real-world applications.
- Designing the right reward is tricky. The "reward function" seems simple, but getting it wrong can lead to bizarre, unintended behavior. If you reward a cleaning robot just for picking up trash, it might learn to just hoard trash in a corner instead of actually putting it in the bin.
- The Exploration vs. Exploitation dilemma. The agent has to constantly decide whether to try something new (explore) to potentially find a better reward, or stick with what it already knows works well (exploit). Balancing this is a constant challenge.
Managing these kinds of complex, data-heavy initiatives is a huge part of the job. For a deeper look into structuring this kind of work, our guide on data science project management offers some great frameworks.