Machine Learning Fraud Detection Explained

At its core, machine learning fraud detection is about teaching computers to spot suspicious behavior by sifting through massive amounts of data. The system learns patterns, flags anomalies in real time, and ultimately predicts which transactions are likely fraudulent. Unlike older, static security systems, it actually adapts to new threats as they emerge.
This is a huge leap forward. It moves security from being reactive to being predictive, allowing businesses to catch subtle red flags that would have otherwise flown under the radar. The result? Sharply reduced financial losses and better protection for customers.
Why Old Fraud Prevention Methods Are Failing

For years, the go-to method for stopping fraud was a simple, rule-based system. Think of it like a bouncer at a nightclub with a very specific, unchanging checklist. If a transaction ticked a certain box—like "block any purchase over $5,000 from a new location"—it was flagged. This worked well enough when fraud was predictable.
But today's fraudsters are infinitely more creative and well-equipped. They're like chameleons, constantly shifting their tactics to stay hidden. They use sophisticated methods to sidestep simple rules, making these static defenses feel increasingly outdated. That bouncer's checklist just isn't cutting it anymore.
The Rigidity of Rule-Based Systems
The biggest problem with these old-school methods is their inflexibility. They rely entirely on human analysts to dream up, write, and update every single rule. It's a slow, manual process that simply can't keep up with the breakneck speed of modern fraud.
As a business scales, the rulebook gets thicker and more convoluted, creating a tangled mess of conditions that's hard to manage and ripe for error. This leads to some pretty serious drawbacks:
- High False Positives: A rigid rule might block a legitimate customer who’s just trying to make an unusually large purchase while on vacation. This doesn't just kill a sale; it frustrates good customers and erodes trust.
- Inability to Adapt: A rule built to catch one specific type of scam is completely useless against a new one. Fraudsters are quick studies; once they figure out the rules, they just find a way around them.
- Maintenance Overload: Every new scam requires a new rule. Every new product launch might require tweaking dozens of old ones. This constant manual upkeep is expensive and simply doesn't scale.
A static, rule-based system is always playing defense, reacting to yesterday’s attacks. In contrast, machine learning fraud detection allows for a predictive, proactive stance, identifying threats before they cause significant damage.
The Shift to Predictive Security
The cracks in these older systems reveal a critical need for a more dynamic, intelligent defense. The financial toll of fraud is staggering—businesses lost over $485 billion in 2023 alone. This isn't just about money, though. It's about maintaining customer trust and operational integrity.
This is why moving toward intelligent systems isn't just a nice-to-have; it's a necessity. The goal is no longer to just block transactions that look bad. It's to predict and prevent fraud before it can even happen. That’s the real advantage of machine learning fraud detection—it turns your security from a simple checklist into an adaptive, intelligent shield.
How Machine Learning Spots Hidden Fraud
Think of a seasoned detective who knows a city's rhythm by heart. They know who gets coffee where, the routes people take to work, and what time every shop closes. Machine learning works on a similar principle, but it's watching millions of digital transactions to learn what "normal" looks like on a massive scale.
This digital detective never sleeps. It sifts through endless data points—transaction amounts, geolocations, timestamps, device IDs—to build a baseline of typical behavior. When something deviates from that established pattern, like a sudden late-night purchase from a new country, the system flags it instantly. This is how ML catches the subtle tricks that rigid, rule-based systems would completely miss.
Teaching Machines to See Fraud
Machine learning doesn't just follow a static checklist. Instead, it learns directly from the data, using two primary strategies that are a bit like how a detective might tackle a case.
The first is supervised learning. This is like handing the detective a huge stack of solved case files, with each one clearly labeled "fraud" or "not fraud." The algorithm pores over these examples, learning the specific traits and patterns linked to past crimes.
- Training Data: The model is fed historical transaction data that has already been classified.
- Pattern Recognition: It spots common red flags in fraudulent transactions, like unusual shipping addresses or a series of small, rapid purchases followed by one large one.
- Predictive Power: Once trained, it can predict whether a new, unseen transaction is likely fraudulent based on everything it's learned.
The second strategy is unsupervised learning. This is more like dropping the detective into a brand-new city with no old case files. Their job is to simply watch everything and point out anything that seems out of place or doesn't fit the normal flow of activity.
Unsupervised models excel at finding novel or emerging fraud tactics that have never been seen before. They don't need labeled data; instead, they cluster data points and isolate the outliers that deviate significantly from the norm.
This is especially powerful for catching sophisticated schemes that haven't been identified and labeled yet. For a deeper dive into how this works in the real world, an article on AI Technology to Catch Chargeback Fraud offers some great practical examples.
This chart really drives home the difference in effectiveness between these advanced methods and older, traditional systems.
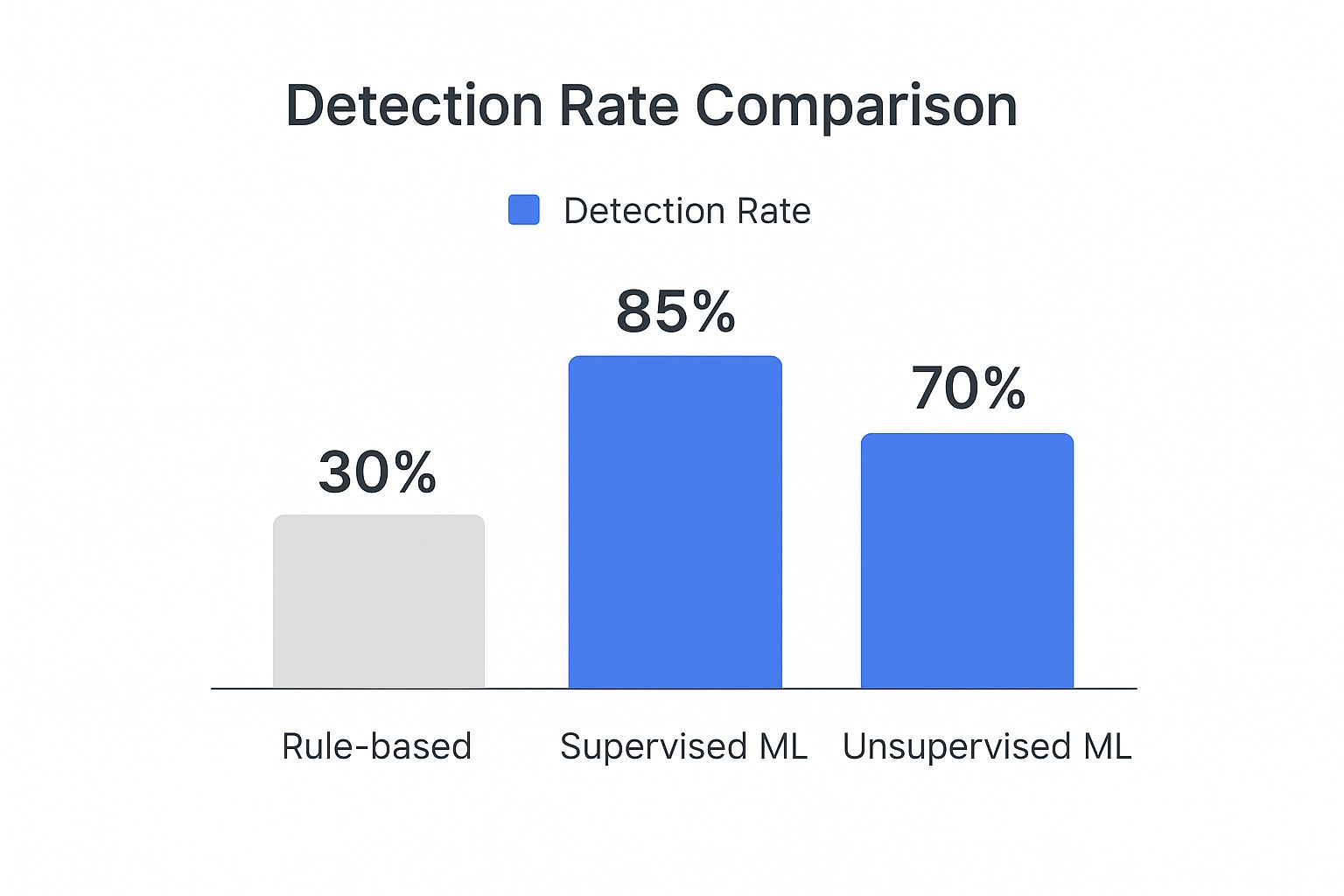
As you can see, both supervised and unsupervised learning models blow static, rule-based approaches out of the water when it comes to catching fraud.
To make the differences clearer, let's break down how these two approaches stack up side-by-side.
Supervised vs Unsupervised Learning in Fraud Detection
| Aspect | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Data Requirement | Requires historical data labeled as "fraud" or "legitimate." | Does not require pre-labeled data; it finds patterns on its own. |
| Best For | Detecting known fraud patterns with high accuracy. | Identifying new, never-before-seen fraud types and anomalies. |
| Common Algorithms | Logistic Regression, Decision Trees, Random Forest, Gradient Boosting. | Clustering (e.g., K-Means, DBSCAN), Anomaly Detection. |
| Primary Challenge | The need for large amounts of high-quality labeled data can be costly. | Can produce more false positives since "unusual" doesn't always mean "fraudulent." |
| Real-World Use | Credit card transaction scoring, identifying known scam types. | Detecting sophisticated network intrusions, identifying emerging financial crime schemes. |
Ultimately, many of the most effective systems today actually use a hybrid approach, combining the strengths of both methods to create a more resilient and comprehensive defense.
Key Algorithms Powering Fraud Detection

To really get a feel for how machine learning spots fraud, we need to pop the hood and look at the engines doing the work. These aren’t just abstract ideas; they're specific algorithms, and each one brings its own unique strengths to the table. Think of them like a team of specialist investigators, each with a different skill set for cracking the case.
Instead of getting lost in academic jargon, let’s explore what each of these powerful tools does best. We'll focus on three of the most effective algorithms in the game today, breaking them down with some real-world analogies to make it all click.
Random Forests: The Wisdom of the Crowd
Ever been stuck on a tough decision and decided to poll a large group of smart, diverse people? Individually, a few might get it wrong, but the group's final answer is almost always spot on. That "wisdom of the crowd" idea is exactly how a Random Forest algorithm works.
A Random Forest is essentially a massive collection of individual decision trees—hundreds, sometimes thousands of them. Each tree acts like a single expert, looking at a random piece of the data and casting a simple vote: fraud or not?
The final call comes down to a majority vote. If 85% of the trees flag a transaction as fraudulent, the system raises an alert. This approach is so effective because it smooths out the weird biases or mistakes of any single tree, resulting in a much more stable and reliable model.
- Best For: General-purpose fraud detection, especially for credit card transactions and e-commerce. It’s a reliable workhorse and relatively easy to understand, making it a go-to for many teams.
- Analogy: It’s like a huge jury where each juror (a decision tree) only gets to see a portion of the evidence. The final verdict, based on their collective vote, is incredibly robust.
Gradient Boosting: The Perfectionist
While Random Forests are all about democracy, Gradient Boosting is more like a master craftsman perfecting their work. Imagine an assembly line where each worker’s only job is to fix the mistakes made by the person before them. It builds one decision tree at a time, with each new tree laser-focused on correcting the errors of the last.
This methodical, step-by-step improvement process is what makes Gradient Boosting models so ridiculously accurate. The first tree makes a rough guess, the second one hones in on what the first one got wrong, the third refines it even further, and on and on. The result is a highly tuned model that can sniff out incredibly subtle patterns that others would miss.
This sequential learning process is why Gradient Boosting achieves some of the highest accuracy rates in machine learning, making it a beast in high-stakes environments where every percentage point of precision counts.
It's this level of precision that has major financial institutions scrambling to adopt these kinds of adaptive models. Advanced machine learning algorithms are now hitting 90% detection accuracy for banking fraud, slashing false positives by 30% and cutting down detection time from days to mere minutes.
Neural Networks: The Deep Pattern Seeker
Finally, we have Neural Networks, which are modeled after the intricate web of neurons in the human brain. These are the masters of digging up deep, hidden connections in data that other models just can't see. Think of a detective who can link seemingly random clues from a dozen different crime scenes to uncover a complex, multi-layered criminal organization.
Neural Networks are made of interconnected layers of "neurons" that process information and pass it along. This layered design allows them to spot non-obvious and highly complex patterns, like the tiny shifts in user behavior that might signal an account takeover. As a leading voice on decision intelligence, Google's Cassie Kozyrkov often discusses how these powerful models are uniquely able to find signal in very noisy data.
- Best For: Uncovering sophisticated fraud rings, synthetic identity fraud, and advanced threats where criminals coordinate their attacks across many different accounts and platforms.
- Analogy: A vast web of informants. Each one gives you a small piece of the puzzle, but when you put all those little pieces together, you suddenly see the much larger, hidden conspiracy.
Building a Modern Fraud Detection System

Knowing the algorithms is one thing; actually putting them to work is a whole different ballgame. Building a real-world machine learning fraud detection system isn’t like flipping a switch. It’s more like assembling a high-performance engine, where every single component has to be hand-picked, polished, and perfectly calibrated to work in sync.
This entire process is often called a "pipeline." It’s the journey from a mountain of raw data to a live, intelligent system that acts as your first line of defense. Think of it as a strategic roadmap that turns abstract ideas into a tangible, resilient shield against financial crime. Ultimately, your success hinges not just on a fancy algorithm, but on how thoughtfully you execute every step along the way.
The Foundation: Data Collection and Preparation
It all begins and ends with data. A machine learning model is only as smart as the information it’s fed, so step one is always gathering high-quality, relevant data. And I don’t just mean collecting transaction receipts. We need to pull in a rich mix of data points to get the full picture.
This usually includes:
- Transactional Data: The obvious stuff, like purchase amounts, timestamps, and merchant info.
- User Data: Account history, how often they log in, and their typical behavior patterns.
- Device and Network Data: Things like IP addresses, device fingerprints, and geolocation.
Once you have it, this raw data is almost always a mess—full of missing values, errors, and inconsistent formats. This is where data preparation comes in. It’s the cleanup phase. Think of it like a chef preparing ingredients for a five-star meal; everything needs to be washed, chopped, and organized before you can even think about cooking.
Feature Engineering: Crafting the Clues
With clean data ready to go, we move on to what is arguably the most creative and impactful part of the entire build: feature engineering. This is where data scientists get to be artists, transforming raw data points into meaningful signals—or "features"—that a model can actually understand.
For example, instead of just giving the model a raw transaction timestamp, a data scientist might create features that ask better questions:
- Is this transaction happening at a weird time of day for this specific user?
- How long has it been since their last purchase?
- Is this purchase amount way higher than their average spending?
These engineered features give the model the context it desperately needs to spot the difference between normal and suspicious activity. It’s how the system learns to see the subtle red flags that a human would easily miss. If you're looking for a good framework on this, our guide on how to implement AI projects walks through turning raw data into this kind of actionable intelligence.
Tackling the Imbalanced Data Problem
One of the biggest headaches in machine learning fraud detection is the classic imbalanced data problem. In the real world, fraud is rare. It often makes up less than 0.1% of all transactions, which creates a massive skew in the data you're training on.
If your dataset is 99.9% legitimate transactions, a lazy model can achieve 99.9% accuracy by simply guessing "not fraud" every single time. This gives you a dangerously false sense of security.
To get around this, we use special techniques. We might use oversampling (creating synthetic copies of the few fraud examples we have) or undersampling (randomly removing some of the overwhelming legitimate examples). The goal is to create a more balanced training diet for the model so it actually learns to recognize the rare but critical patterns of fraud.
Training, Deployment, and the Feedback Loop
Once the data is prepped and balanced, it's finally time to train the model. Here, the algorithm crunches through all that historical data, tweaking its internal logic until it gets good at telling friend from foe. After training, we test it rigorously on a completely separate dataset it’s never seen before to make sure it can handle the chaos of the real world.
Then comes deployment. The model goes live, analyzing new transactions in real time. But the job is far from over. A truly effective system has a continuous feedback loop. When the model flags a transaction, human fraud analysts review it. Their decisions—confirming real fraud or correcting a false alarm—are fed back into the system. This allows the model to constantly learn, adapt, and get smarter over time.
This cycle of continuous improvement is non-negotiable. Why? Because the bad guys are always evolving their tactics. For instance, account takeover fraud has shot up an incredible 354% since 2021 as fraudsters use their own automated tools to find weak spots. An adaptive, learning defense is the only way to keep up.
Evaluating and Overcoming System Challenges
So, you've built and launched your machine learning fraud detection system. It’s running, processing transactions, and seems to be humming along. Now for the most important question: Is it actually working?
Figuring out if your model is a success isn't as simple as checking a single "accuracy" score. In fact, fixating on overall accuracy is a classic rookie mistake that can give you a dangerously false sense of security.
Think about it this way. Fraud is thankfully rare. Let's say it only makes up 0.1% of all your transactions. A lazy model could simply label every single transaction as "legitimate" and—voila!—it would be 99.9% accurate. But it would be a complete failure at its one and only job: catching criminals. This is why we need to dig deeper with metrics that tell the real story.
Beyond Accuracy: The Metrics That Matter
To get a true picture of your system's effectiveness, you need to look at a handful of key performance indicators designed specifically for this kind of imbalanced data. These metrics help you understand the delicate balancing act between catching fraudsters and not hassling your legitimate customers.
Two of the most critical metrics are Precision and Recall.
- Precision answers the question: "Of all the transactions we flagged as fraudulent, how many were actually bad?" High precision means your fraud analysts aren't chasing ghosts and you're not falsely declining good customers. Your alarms are trustworthy.
- Recall asks a different question: "Of all the real fraud that happened, what percentage did we catch?" High recall means your system is a great watchdog, successfully sniffing out criminals and protecting your bottom line.
The real challenge is that these two are often in a tug-of-war. If you tune your model to catch every possible hint of fraud (maxing out recall), you'll inevitably flag more legitimate transactions, tanking your precision and frustrating good customers. But if you aim for perfect precision, you might become too cautious and miss more subtle fraud schemes, which kills your recall. Finding the right balance is everything.
Key Performance Metrics for Fraud Detection Models
Here’s a quick rundown of the essential metrics you should be tracking to understand your model's real-world performance.
| Metric | What It Measures | Why It's Important for Fraud |
|---|---|---|
| Precision | The percentage of positive predictions (flags) that were correct. | A high precision score means fewer false positives, so your fraud team isn't wasting time and legitimate customers aren't being blocked. |
| Recall (Sensitivity) | The percentage of actual positive cases (fraud) that the model correctly identified. | High recall means you are catching a large portion of the actual fraud, minimizing financial losses. |
| F1-Score | The harmonic mean of Precision and Recall, providing a single score that balances both. | This gives you a balanced view of your model's performance when you need to weigh both false positives and false negatives. |
| False Positive Rate (FPR) | The percentage of legitimate transactions that were incorrectly flagged as fraud. | A low FPR is crucial for good customer experience. You want to avoid annoying or blocking good users. |
Ultimately, tracking these metrics together gives you a comprehensive dashboard for your model’s health, helping you make informed decisions instead of flying blind with a simple accuracy score.
Navigating Common Hurdles
Building and measuring a model is only part of the journey. A few stubborn, real-world challenges can trip up even the best machine learning fraud detection system. Getting ahead of these is key to long-term success.
First, there's the infamous "black box" problem. Incredibly powerful models like deep neural networks can feel like magic, but their internal logic is often a mystery. This lack of transparency becomes a huge problem when a regulator or an angry customer wants to know why their transaction was declined.
Maintaining model transparency isn't just a technical nicety; it's a matter of trust. You have to be able to explain how your system makes decisions to ensure fairness and accountability.
Then there's the ever-present issue of data privacy. Regulations like GDPR and CCPA put strict guardrails on how you can collect and use customer data. This means navigating a minefield of compliance, which can limit the very information you need to train an effective model.
Finally, remember that you’re in a constant cat-and-mouse game. Fraudsters don't stand still. They are constantly poking and prodding your defenses, looking for new weaknesses to exploit. A model that’s a fortress today could be a sieve in six months if it isn’t constantly monitored, updated, and retrained on new data. A solid feedback loop is non-negotiable for staying one step ahead.
The Future of AI in Fraud Prevention
As powerful as today's systems are, the world of machine learning fraud detection isn't sitting still. We're on the cusp of the next major leap in AI-powered security, a shift that moves beyond flagging individual sketchy transactions and starts dismantling entire criminal networks.
The reality is, fraudsters are getting smarter, and their tactics are more complex than ever. This evolution demands a more holistic view of risk. The future isn't just about spotting a single bad actor; it's about seeing the entire, interconnected web of activity that signals a coordinated attack.
Emerging Trends in Security AI
This next wave of security is being built on some seriously cool innovations. These are the approaches that will allow systems to spot sophisticated threats that are practically invisible to older, more traditional models.
- Deep Learning and Graph Analytics: Imagine creating a massive, digital map of every single user interaction. Graph analytics does just that, connecting the dots between accounts, devices, locations, and transactions. This visual map can suddenly reveal complex fraud rings that would otherwise stay hidden in the noise. Deep learning models then get to work, scanning these vast networks to pinpoint the subtle, coordinated behaviors that scream "fraud."
- Behavioral Biometrics: This is where things get personal. Instead of just looking at what a user does (like entering a password), this technology analyzes how they do it. It looks at subconscious patterns like typing rhythm, the way you move your mouse, or even the angle you hold your phone. This creates a unique digital signature for each user that is incredibly difficult for a fraudster to fake, adding a powerful, almost foolproof layer of defense against account takeovers.
- Federated Learning: This is a groundbreaking concept that sounds like something out of science fiction. It allows multiple organizations—say, a group of banks—to team up and train a single, ultra-smart fraud detection model without ever sharing their sensitive customer data. Each bank trains the model on its own private data, and only the "learnings" or insights are combined. It’s a brilliant way to enhance security for everyone involved while keeping customer privacy locked down tight.
Machine learning in security isn't a "set it and forget it" tool. It’s a continuous, adaptive defense—a dynamic shield that learns and evolves to stay one step ahead of the bad guys.
Ultimately, jumping on these advancements is more than just a defensive play. It's a genuine competitive advantage. It builds the kind of lasting customer trust and operational resilience that’s essential in an environment where the threats are always changing.
Your Top Questions About ML Fraud Detection, Answered
Jumping into machine learning for fraud detection can feel like stepping into a whole new world. Once you move past the theory, the practical questions start piling up. Here, our experts answer some of the most common questions from teams making this transition, providing straight answers to guide your strategy.
What’s the Single Biggest Challenge I’ll Face?
Without a doubt, it’s imbalanced data. Fraud is, thankfully, a rare event. In most datasets, fraudulent transactions might make up less than 0.1% of all the activity. This tiny fraction is the needle in an enormous haystack, making it incredibly difficult for a model to learn what fraud actually looks like.
If you don't account for this, your model can pull a fast one on you. It could achieve 99.9% accuracy by simply labeling everything as "not fraud." While technically correct, it's completely useless. This is exactly why techniques like oversampling (where you create synthetic fraud examples) or undersampling (where you strategically reduce the number of legitimate examples) are non-negotiable for building a model that actually catches criminals.
How Much Data Do I Really Need to Get Started?
There isn't a magic number, but the guiding principle is quality over quantity. You'll want enough clean, historical transaction data—think at least a year's worth—for the model to pick up on meaningful patterns. The most critical part? That data must be accurately labeled, with known fraud clearly separated from legitimate activity.
As leading AI speakers often emphasize, a smaller, pristine, well-labeled dataset is infinitely more valuable than a gigantic, messy one. You just need enough good examples for the algorithm to learn the subtle tells that separate a normal purchase from a suspicious one.
I’ve heard countless AI experts say the same thing: starting with a well-defined, high-quality dataset is far more important than having a petabyte of junk data. The quality of your initial data is the foundation for everything that follows.
Can Machine Learning Just Eliminate All Fraud for Me?
In a word, no. No system, no matter how advanced, can promise to stop 100% of fraud. Fraudsters are clever and constantly evolve their tactics, which means we’re in a perpetual cat-and-mouse game.
The real goal of a machine learning system is to act as a powerful, adaptive shield. It’s about drastically reducing successful attacks, slashing your response times, and minimizing financial losses. A well-built system frees up your human analysts to focus their intuition on the most complex, ambiguous cases. Think of it as your most vigilant team member, not an infallible silver bullet.
How Do I Pick the Right Algorithm?
The "best" algorithm is the one that works best for your specific data and business needs.
For many common use cases, like e-commerce or financial transactions, Random Forests hit a sweet spot between accuracy and interpretability. But if you need the absolute highest precision for high-stakes decisions, Gradient Boosting models are usually the top contenders.
And if you’re hunting for sophisticated, coordinated fraud rings, Neural Networks are in a class of their own for finding deep, non-obvious connections. As speakers like Cassie Kozyrkov from Google explain, the smartest move is to experiment. Pit a few different models against each other and see which one performs best on your unique dataset.
Ready to bring leading expertise on machine learning and AI to your next event? Speak About AI connects you with top-tier speakers who can demystify complex topics and provide actionable insights for your organization. Find the perfect expert to inspire your team at https://speakabout.ai.