Supervised Learning vs Unsupervised Learning: A Quick Guide

The core difference really boils down to this: supervised learning uses labeled, organized data to make predictions, a bit like a student learning with an answer key. On the other hand, unsupervised learning dives into unlabeled data to find hidden patterns, more like a detective connecting dots without any initial clues. Your choice hinges on whether you're trying to predict an outcome or discover something new.
Decoding The Core Concepts Of Machine Learning

To really get a feel for supervised and unsupervised learning, it helps to see where they fit within the broader field of Artificial Intelligence. These two methods are the foundational pillars of modern machine learning, and each one gives us a completely different way to pull value from data. While they solve different kinds of problems, they both fuel the powerful AI capabilities we see today.
The real dividing line is the kind of data each model needs. Supervised learning demands a dataset where every single data point is tagged with a correct answer. As many of our expert speakers explain, think of it as teaching a computer by showing it thousands of examples and giving it the solutions. This "supervision" is what lets the model learn the relationship between inputs and outputs, so it can make accurate predictions on new data it’s never seen before.
Unsupervised learning, however, works with data that has no labels at all. Its job isn't to predict a known outcome but to find the inherent structures, clusters, or weird outliers hiding in the data itself. It’s an exploratory process that helps businesses understand their data on a much deeper level.
If you're curious about another learning style, we also have a guide that explores https://speakabout.ai/blog/what-is-reinforcement-learning and how it compares.
Supervised vs Unsupervised Learning At A Glance
Choosing the right approach is a make-or-break decision for any AI project. When you look at market trends, you’ll see that over 70% of machine learning projects in major companies rely on supervised learning, mostly because it delivers incredibly high accuracy when you have good, clean, labeled data.
"Understanding the supervised versus unsupervised learning trade-off isn't just a technical decision; it's a strategic one. The right choice depends entirely on your business goal—are you trying to answer a specific question with historical data, or are you looking for questions you didn't even know you should be asking?" - An insight frequently shared by our AI strategists.
Our roster of AI speakers excels at breaking these concepts down for business leaders, translating complex technical details into practical, actionable strategies.
To make this even clearer, here's a quick side-by-side comparison:
| Attribute | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Input Data | Requires labeled data (input-output pairs). | Uses completely unlabeled data. |
| Primary Goal | To predict a specific outcome or classify data. | To discover hidden patterns and structures. |
| Common Algorithms | Linear Regression, Decision Trees, SVM. | K-Means Clustering, PCA, Anomaly Detection. |
| Human Role | Significant effort in data labeling and training. | Focuses on interpreting the model's findings. |
Ultimately, this table shows that the human role shifts dramatically. With supervised learning, the heavy lifting is upfront in labeling the data. With unsupervised learning, the real work begins after the model runs, as your team has to interpret the patterns it uncovers and decide what they mean for the business.
How Data Requirements Shape Each Approach

The single biggest factor in the supervised vs. unsupervised learning debate is the data itself. What you have—or what you can get—determines which path you can take and what problems you can realistically solve. One approach needs a teacher, while the other is built for pure exploration.
Supervised learning is entirely dependent on labeled data. Picture it like teaching a toddler with flashcards. Each card has a picture (the input) and the correct word on the back (the label). For an algorithm to learn effectively, it needs to see thousands, sometimes millions, of these perfect examples.
This "supervision" is what allows the model to connect specific inputs to specific outputs with incredible accuracy. But the quality and quantity of those labels are everything. Without them, the algorithm has no ground truth to learn from. Before you even start, it's worth exploring different data acquisition strategies for AI, because getting this raw material is step one.
The Power and Price of Labeled Data
The need for labeled data isn't just a technical detail; it's a major operational hurdle. Labeling data is usually a manual, resource-heavy task that requires human experts to painstakingly tag images, categorize text, or assign values. It can get expensive and time-consuming, fast.
The reward for that upfront investment, however, is precision. A well-trained supervised model can predict outcomes with stunning accuracy, making it the perfect choice for tasks with clearly defined goals.
"Your data strategy is your AI strategy. The decision to invest in labeling data for supervised learning isn't just a technical choice; it's a business commitment to achieving highly specific, predictable outcomes." - A key takeaway from our data science experts.
Many of our speakers find that organizations consistently underestimate the sheer effort involved in data prep. An expert with a background in predictive analytics can offer a realistic roadmap for building a high-quality labeled dataset, ensuring your project is set up for success from the very beginning.
Thriving in the Unlabeled Wilderness
Unsupervised learning lives on the other side of the data spectrum. It works with unlabeled data, which is far more common and much easier to get your hands on. In fact, an estimated 80-90% of all data generated today is unstructured and unlabeled, which is a massive untapped reservoir of insights.
This approach is like handing an algorithm a giant, messy library and asking it to sort the books by topic without a catalog. The model sifts through everything, finds inherent similarities and differences, and groups related things together. It isn't trying to predict a "right" answer; it's trying to discover the hidden structure in the data itself.
This makes unsupervised learning a phenomenal tool for discovery. When you're not exactly sure what you're looking for, it can uncover hidden customer segments, spot weird network activity, or identify natural clusters in your product catalog.
Key Data Implications for Your Business
The choice between these two models directly impacts your budget, timelines, and the kinds of questions your business can answer. The table below breaks down the practical side of each data requirement.
| Data Consideration | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Data Preparation | High effort and cost; requires extensive manual labeling and domain expertise. | Low effort; works with raw, unlabeled data as-is, minimizing preparation time. |
| Data Volume | Often requires large volumes of labeled data to achieve high accuracy. | Can derive insights from large volumes of unlabeled data, which is more readily available. |
| Primary Insight | Predictive: Answers specific questions like "Will this customer churn?" or "What will sales be next quarter?" | Exploratory: Uncovers patterns and relationships, answering questions like "What are our natural customer groups?" |
| Expertise Needed | Requires data scientists skilled in feature engineering and model training on labeled datasets. | Needs experts who can interpret the discovered patterns and translate them into business value. |
Data Consideration | Supervised Learning | Unsupervised Learning
An AI expert speaker can be a game-changer here. A speaker who specializes in unsupervised learning can teach your team how to make sense of complex clusters, while a supervised learning pro can advise on the most efficient labeling techniques. Their insights make sure your data strategy lines up perfectly with your business goals, helping you avoid costly mistakes on your AI journey.
Comparing Key Algorithms and Their Complexity
When you peel back the layers of supervised and unsupervised learning, you get to the engines driving everything: the algorithms. Think of them as the specific recipes your system follows. Each learning style has its own toolkit, and the algorithm you pick has a direct impact on the complexity, cost, and timeline of your project. This is a point our AI speakers drive home constantly when they’re advising companies on where to start.
The choice isn't just a technical detail—it's a strategic one. Some algorithms are quick and dirty, great for getting a baseline. Others are computational heavyweights that require serious processing power and a lot of fine-tuning to get right.
Common Algorithms in Supervised Learning
In supervised learning, the name of the game is prediction. The algorithms are all designed to learn a mapping function from your labeled inputs to a known output. Two of the most common workhorses here are Linear Regression and Support Vector Machines (SVMs).
- Linear Regression: This is one of the simplest predictive algorithms out there. It literally finds the best-fitting straight line to describe the relationship between your inputs and the target you want to predict. Because of its low computational complexity, it's incredibly fast to train, even with massive datasets. It’s perfect for forecasting tasks like estimating sales based on ad spend.
- Support Vector Machines (SVMs): A big step up in complexity, SVMs are powerhouses for classification. An SVM finds the optimal "hyperplane"—think of it as a decision boundary—that best separates your data points into different categories. It’s the kind of algorithm that can decide if an email is "spam" or "not spam." It's more computationally demanding than linear regression but often delivers much higher accuracy, especially with messy, non-linear data.
These algorithms need labeled data to function. That "ground truth" is what allows them to be trained, tested, and validated, which is why supervised models can often achieve such high accuracy.
One of the key statistical distinctions between supervised and unsupervised learning lies in their dataset requirements and resulting accuracy. Supervised learning relies on labeled data, where each input is matched with a known output. This crucial factor contributes to higher accuracy in tasks such as classification and regression... In contrast, unsupervised learning utilizes entirely unlabeled data, working to discover hidden patterns without predefined categories or outcomes. Because it analyzes raw data without direct guidance, the accuracy of unsupervised models is generally lower and more variable. You can explore a detailed tutorial on these statistical differences on ifoadatascienceresearch.github.io.
Unsupervised Learning Algorithms and Their Power
Unsupervised learning operates in the wild, with no labels to guide it. Its job is to find the hidden structures and patterns buried in the data. The algorithms here are built for exploration, making them ideal for tasks like segmentation and dimensionality reduction.
The two main players you'll hear about are K-Means Clustering and Principal Component Analysis (PCA).
- K-Means Clustering: This is the go-to algorithm for segmentation. You tell it how many clusters (the "K") you want to find, and it groups your unlabeled data points into that many distinct groups based on similarity. Businesses use this all the time to find customer segments for targeted marketing campaigns. Its complexity scales with the size of the dataset and the number of clusters, but it’s a surprisingly efficient way to start exploring your data.
- Principal Component Analysis (PCA): PCA is all about making complex data simpler. It reduces the number of variables in your dataset down to a smaller set of "principal components" that still contain most of the original information. It's a lifesaver for cleaning up noisy data and can dramatically speed up other machine learning tasks. While its complexity is tied to the dataset's size, it's an indispensable tool for data preparation.
The algorithms in both learning styles are often the building blocks for much bigger, more advanced systems. To see how these foundational ideas fit into the broader landscape, check out our guide on the differences between deep learning vs machine learning. In the end, picking the right algorithm always comes down to a trade-off between simplicity, cost, and the accuracy you need to solve your specific business problem.
Real-World Applications and Business Use Cases
Knowing the theory behind the supervised vs unsupervised learning debate is one thing. Seeing how these models actually drive business value is another entirely. As our speakers often demonstrate, the model you choose directly dictates the kinds of problems you can solve—from predicting future sales with high accuracy to discovering entirely new market segments hiding in plain sight.
The most successful AI initiatives don't start with the model; they start with a clear business goal. Only then can you align the model's strengths to the objective.
Supervised Learning In Action
Supervised learning is your go-to when the goal is crystal clear and you have the historical data to prove it. It's the engine running behind the scenes of many automated decisions that make modern business possible.
Think about it. The systems that keep your inbox clean or your financial data secure? Most of them are classic examples of supervised learning.
- Email Spam Filtering: This is probably the most relatable example. Spam filters are trained on millions of emails that humans have already labeled as "spam" or "not spam." The model learns what to look for—suspicious keywords, odd sender patterns, weird links—and then automatically sorts your incoming mail with stunning accuracy. It's a simple, powerful application of predictive classification.
- Credit Risk Assessment: When you apply for a loan, banks aren't just guessing. They're using supervised models trained on decades of historical loan data. Each past loan is a data point, complete with applicant information and the ultimate outcome: did they pay it back or default? By learning from these examples, the model can assign a reliable risk score to new applicants, helping lenders make smarter, data-backed decisions.
These use cases work because they're not about exploration. They're about making an accurate prediction based on a mountain of labeled evidence.
Uncovering Opportunities With Unsupervised Learning
Where supervised learning needs a map, unsupervised learning thrives in uncharted territory. It’s the perfect tool for discovery, helping businesses find valuable patterns and structures they never knew existed.
Its applications are all about generating insights from the ground up, without any preconceived notions.
- Customer Segmentation: Retailers and marketers are swimming in customer data. Unsupervised clustering algorithms can dive into that sea of purchasing behaviors, demographics, and browsing history to find natural groupings. The model doesn't need to be told what to look for; it identifies segments like "high-value loyalists," "weekend bargain hunters," or "first-time visitors" on its own. This allows marketing teams to stop guessing and start creating campaigns that speak directly to each group.
- Anomaly Detection for Fraud Prevention: Sure, supervised models are great at spotting the same old fraud patterns. But what about new, sophisticated attacks? That's where unsupervised learning shines. By first learning what "normal" transaction behavior looks like, an anomaly detection model can instantly flag anything that deviates from that baseline. This is absolutely critical for catching clever fraud schemes that don't fit historical patterns.
These examples show how unsupervised learning creates value by bringing order to chaos. It turns raw, unlabeled data into strategic business intelligence.
"Many organizations get stuck trying to force a predictive model on a discovery problem. A key part of our advisory work is guiding leaders to first ask: 'Are we trying to answer a known question, or are we looking for the right questions to ask?' That simple distinction often points directly to either supervised or unsupervised learning." - A frequent insight from our expert AI speakers.
Our speakers have guided organizations through this exact decision, stressing that the most powerful AI strategies often use both models together. For instance, a company might first use unsupervised learning to segment its customer base. Then, it can build separate supervised models to predict the lifetime value for each newly discovered segment. This hybrid approach combines the exploratory power of one with the predictive precision of the other, creating a much stronger competitive edge.
How to Choose the Right Model for Your Project
Picking the right machine learning model isn't just a technical detail—it's a strategic move that can make or break your entire project. The choice between supervised and unsupervised learning hinges on your core business objective, the data you actually have, and what a "win" looks like for your team. A wrong turn here often leads to wasted time and projects that never quite deliver on their promise.
The entire decision boils down to one simple question: Are you trying to predict or discover?
If you need to forecast a specific, known outcome—like next quarter’s sales numbers or which customers are about to churn—you're in the world of prediction. This requires a clear target and a history of data where that target is already known.
On the other hand, if you're trying to make sense of your data, find hidden structures, or answer questions you don’t even know to ask yet, your goal is discovery. This is pure exploration. You might want to find natural customer segments or spot unusual activity in your network logs without having a predefined outcome in mind.
Your Data Is the Deciding Vote
The data you have on hand is your next reality check. Do you have a clean, reliable dataset where the "answers" are already present? We call this labeled data, and it’s the fuel that makes supervised learning run. For instance, a historical log of loan applications is only useful for predicting defaults if every single application is clearly marked as "defaulted" or "paid in full."
If all you have is a massive pile of raw, unlabeled information—think thousands of customer reviews or streams of sensor data—then unsupervised learning is where you have to start. The sheer cost and effort to manually label a huge dataset can be a non-starter, making an exploratory approach far more practical.
"The most common mistake I see is organizations trying to force a predictive model onto a discovery problem. They want the certainty of supervised learning without having the necessary labeled data. The most effective strategies start by honestly assessing the data you have, not the data you wish you had." - A common warning from our AI speakers.
Many of our AI speakers will tell you that a project's fate is sealed long before any code gets written. The key is aligning your technical approach with your business goals and data reality. This is a foundational principle of smart data science project management, and our guide on managing data science projects dives deeper into getting this alignment right from day one.
This simple decision tree can help you visualize the choice based on your main business goal.
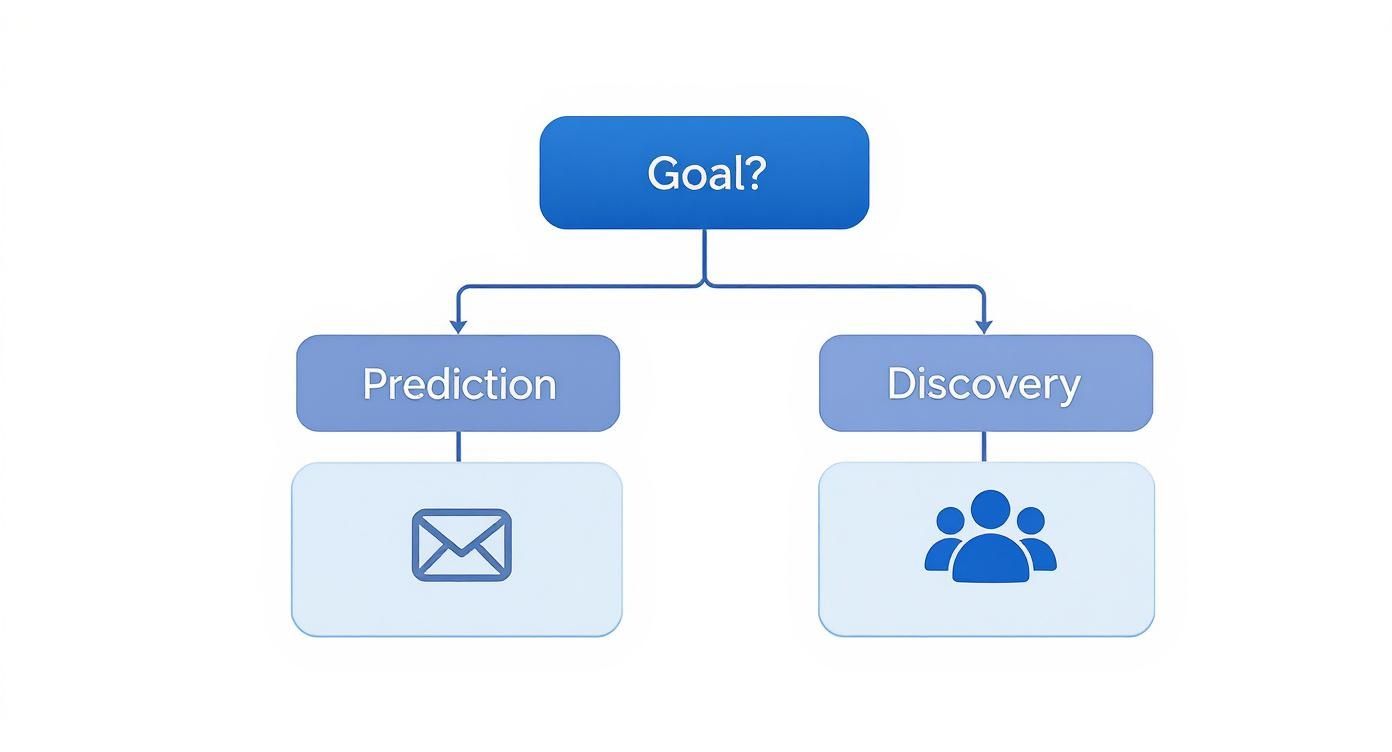
As the graphic shows, it all comes back to your primary intent: are you predicting a known outcome or discovering new patterns?
A Practical Decision Framework
To make this even more concrete, let's put the key factors side-by-side. This simple matrix can act as a quick-start guide for your team when planning your next AI initiative.
Decision Matrix for Choosing Your Learning Model
This table breaks down the choice into practical terms, helping you connect your business needs and data realities to the right machine learning approach.
| Consideration | Choose Supervised Learning If... | Choose Unsupervised Learning If... |
|---|---|---|
| Business Goal | You need to predict a specific, quantifiable outcome (e.g., sales figures, customer churn rate, or stock prices). | Your goal is to explore your data to find hidden patterns, segments, or anomalies without a predefined target. |
| Data Availability | You have a substantial amount of high-quality, labeled historical data relevant to your prediction target. | You have a large volume of raw, unlabeled data and labeling it is impractical or impossible. |
| Question Type | You are asking specific, targeted questions like, "Will this user click the ad?" or "Is this transaction fraudulent?" | You are asking broad, exploratory questions like, "What are the natural groupings of our customers?" or "What is unusual here?" |
| Defining Success | Success is easily measured by comparing the model's predictions against known outcomes (e.g., accuracy, precision). | Success is more subjective and is measured by the value and actionability of the insights the model uncovers. |
In the end, the most powerful approach is often a hybrid one. An AI expert from our network might guide you to first use unsupervised learning to discover new customer segments from your raw data. Then, with those segments defined, you could apply supervised learning to predict the lifetime value within each segment.
This layered strategy combines the strengths of both methods, turning broad discovery into sharp, actionable predictions. It’s how you get the absolute most value out of your data.
Finding an AI Speaker with the Right Expertise
Figuring out the difference between supervised and unsupervised learning isn't just a technical quiz—it's the key to framing your company's strategic goals. But turning that knowledge into action is the hard part. That’s where an expert AI speaker comes in, bridging the gap between dense theory and practical business wins.
The goal is to match a speaker’s deep expertise with your organization’s immediate problems and long-term vision. This ensures your team leaves with actionable frameworks, not just a head full of abstract ideas.
Matching Speaker Expertise to Strategic Goals
To find the right fit, start with your core business objective. Are you trying to sharpen existing processes with better predictions, or are you hoping to uncover brand-new market opportunities buried in your data?
- For Predictive Analytics: If your goal is forecasting sales, plugging customer churn, or flagging financial risk, you need an expert in supervised learning. Our roster features speakers who can walk your team through real-world case studies showing how regression and classification drove measurable ROI.
- For Market Discovery: On the other hand, if you’re trying to decode customer behavior, find hidden market segments, or spot new types of fraud, you’ll want a visionary in unsupervised learning. These experts excel at pulling valuable insights out of raw, unlabeled data, inspiring teams to find opportunities that were completely invisible before.
Our roster includes specialists from both camps, so you can connect with an expert who speaks your language. This turns a keynote from an interesting talk into a genuine strategic asset.
The real value of an AI speaker isn't just explaining what a model does, but illuminating what your business can do with that model. The conversation must shift from technical details to strategic execution.
How Our Speakers Accelerate Your AI Journey
The experts we represent are more than just speakers—they’re partners in your AI adoption journey. They share proven frameworks and stories from their careers at top tech companies and research labs, giving your team invaluable guidance.
A speaker with a background in supervised learning can lay out a pragmatic roadmap for data labeling and model validation, helping you sidestep the common mistakes that derail predictive projects. In the same way, an unsupervised learning expert can give your team the right interpretive skills to turn confusing data clusters into clear business intelligence.
By thinking carefully about the supervised vs. unsupervised learning distinction, you can pick a speaker who doesn’t just educate but empowers your team to move forward with confidence and clarity.
Still Have Questions?
Deciding between supervised and unsupervised learning can feel complicated, especially when you're just getting started with AI. Here are a few common questions we hear from business leaders, along with some straightforward answers.
Is Supervised Learning Better Than Unsupervised Learning?
This is a classic "it depends" situation. Neither approach is inherently better—they're just different tools for different jobs. Think of it like a hammer versus a screwdriver.
Supervised learning is your go-to when you have a specific goal and know what you're looking for. If you want to predict sales figures or identify which customers are likely to churn, and you have historical data to prove it, supervised learning is the clear winner. Its success is all about accuracy.
Unsupervised learning, on the other hand, is built for exploration. It excels when you don't know what you're looking for and need the machine to find hidden patterns for you, like discovering new customer segments you never knew existed. Success here is measured by the quality of the insights it surfaces.
The real question isn't which model is better, but which problem you're trying to solve. An AI speaker with real-world experience can help you match the right tool to your specific business challenge.
What If My Data Is Only Partially Labeled?
You're in luck—this is an incredibly common scenario. It's rare for a company to have perfectly labeled datasets for everything. This is where semi-supervised learning comes into play.
This hybrid model uses your small stash of labeled data to make sense of the much larger pile of unlabeled data. It’s a smart, cost-effective compromise that gives you the accuracy of supervised learning without the massive expense and time commitment of labeling everything by hand.
What Are the First Steps for a Business New to AI?
Jumping into AI doesn't start with code or algorithms. It starts with a clear business problem. If you're new to this, forget the tech for a moment and focus on these three steps.
- Define a High-Impact Goal: Get specific. Don't just say you want to "improve sales." Aim to "reduce customer churn by 10%" or "identify our top three customer personas." A measurable goal is the foundation of a successful project.
- Take an Honest Look at Your Data: What do you actually have? Is it neatly labeled, or is it a raw, unlabeled collection? More importantly, is it clean and reliable? Be realistic about your starting point.
- Talk to an Expert: Before you invest heavily, bring in someone who has done this before. An expert, like one of the AI speakers on our roster, can run a workshop to validate your idea and build a practical roadmap. This simple step can be the difference between a stalled project and a successful launch.
Ready to turn these concepts into a clear, actionable strategy for your organization? The expert speakers at Speak About AI can help your team move beyond the theory and start applying supervised and unsupervised learning to your unique business challenges. Find the perfect AI expert for your next event.