Deep Learning vs Machine Learning A Practical Guide

Here’s the thing: deep learning is a sophisticated type of machine learning. It's a classic "all squares are rectangles, but not all rectangles are squares" situation. All deep learning falls under the machine learning umbrella, but not all machine learning is deep learning.
Think of machine learning as the big-picture field, full of different algorithms that learn from data. Deep learning is a specialized part of that field that uses complex, multi-layered structures—called neural networks—to crack much more intricate problems, often in a way that mimics how we think.
Understanding The Core Differences
At Speak About AI, our roster of expert speakers, from AI ethicists to data scientists, often breaks it down like this: the deep learning vs. machine learning distinction really comes down to hierarchy and capability. Machine learning (ML) covers a wide range of algorithms that typically need structured data and a bit of human guidance. This hands-on process, known as feature engineering, is where a person tells the algorithm which parts of the data are important. It’s incredibly powerful for tasks like predicting customer churn from a spreadsheet or flagging spam emails based on known red flags.
Deep learning (DL), on the other hand, is far more independent. Its artificial neural networks can figure out the important features all on their own, directly from raw, unstructured data like images, text, and audio. This is the magic behind some of today’s most advanced applications, from self-driving cars spotting pedestrians to voice assistants understanding what you say. If you want to get a solid handle on how these fields fit together, these AI, ML, and Deep Learning fundamentals are a great starting point.

The key takeaway is that machine learning needs a guiding hand to interpret data, whereas deep learning systems learn to identify patterns on their own, much like a human would. This self-learning ability is what allows DL to tackle complexity at a massive scale.
This distinction is crucial for any business. As our keynote speakers consistently emphasize, choosing the right method depends entirely on the problem you're trying to solve, the data you have, and what you want to achieve. Knowing how to frame the problem correctly is the first step, a concept we explore in our guide on how to teach artificial intelligence.
Quick Look Machine Learning vs Deep Learning
To make things even clearer, let's put the core differences side-by-side. This table gives you a high-level overview of where these two powerful fields diverge.
| Attribute | Machine Learning | Deep Learning |
|---|---|---|
| Data Dependency | Can perform well with smaller datasets. | Requires large volumes of data to perform effectively. |
| Hardware Needs | Can run on standard CPUs. | Typically requires high-end GPUs for efficient processing. |
| Human Intervention | Often requires manual feature engineering and guidance. | Automates feature detection and learns with minimal oversight. |
| Problem Complexity | Best for simpler, well-defined classification and regression tasks. | Excels at complex problems like image and speech recognition. |
While this table highlights the major contrasts, remember that the choice isn't always black and white. The best approach is always dictated by the unique demands of your project.
Data Requirements And Architecture
One of the clearest dividing lines in the deep learning vs. machine learning debate is data—how much you need and what kind you have. The entire architecture of each approach is built around how it ingests and learns from information. This is a point our expert speakers always stress as a critical first consideration for any AI project.
Traditional machine learning models are superstars with structured, labeled data. They often perform brilliantly with datasets that, by today's standards, might even seem small. Think of a clean spreadsheet with well-defined columns and rows, like customer demographics or equipment sensor logs. For these tasks, an ML algorithm needs a data scientist to perform feature engineering—a manual process of selecting and transforming the most important variables to help the model learn. This human-in-the-loop approach allows ML models to deliver powerful insights with surprisingly modest amounts of data.

The Scale of Deep Learning Data
Deep learning operates on a completely different plane. Its multi-layered neural networks are designed to figure things out on their own, finding complex patterns directly from raw, unstructured data like images, audio, and huge volumes of text. This built-in feature extraction is a massive advantage, but it comes with a price: a voracious appetite for data.
Deep learning models learn hierarchically. For an image, the first layer might learn to see edges, the next layer combines edges into shapes, and the layers after that assemble those shapes into objects like faces or cars. This process requires an enormous volume of examples to work correctly.
This architectural difference creates a stark contrast in resource needs. Deep learning models demand massive datasets—often millions of examples—and serious computational muscle, usually from GPUs. In contrast, traditional machine learning can get the job done with just hundreds or thousands of samples on a standard CPU. For example, a deep learning image classifier might need a dataset like ImageNet, which has over 14 million labeled images. A logistic regression model, however, could predict customer churn with just a few thousand records from a CRM. You can find more details on these ML resource comparisons and what makes them unique.
Hardware and Computational Demands
The consequence of these architectures flows directly into hardware choices. Machine learning algorithms, with their more straightforward math on smaller datasets, are perfectly happy running on standard Central Processing Units (CPUs). They can be deployed across a huge range of business applications without any special equipment.
Deep learning is another animal entirely. The sheer number of parallel matrix multiplications needed to train a deep neural network makes CPUs a non-starter. This is where Graphics Processing Units (GPUs) become non-negotiable.
Here’s a simple way to think about the hardware divide:
- Machine Learning:
* Processor: Runs efficiently on standard CPUs.
* Data Size: Works best with datasets from hundreds to thousands of records.
* Ideal Use Case: Analyzing structured data, like predicting loan defaults from a client's financial history.
- Deep Learning:
* Processor: Needs powerful GPUs (or TPUs) for training in a reasonable timeframe.
* Data Size: Requires datasets in the hundreds of thousands or millions.
* Ideal Use Case: Analyzing unstructured data, such as identifying objects in a live video stream.
Getting a handle on these foundational differences in data and hardware is the first real step in deciding which path makes sense for your project's scope, budget, and ultimate goals.
When Machine Learning Outperforms Deep Learning
In the deep learning vs machine learning debate, it’s easy to assume that newer, more complex models are always the answer. But many of our speakers make a crucial counterpoint: for a massive slice of business applications, traditional machine learning isn’t just good enough—it’s actually the better choice.
This is especially true when you're working with structured, tabular data. Think spreadsheets and databases, the bread and butter of most companies.
This kind of data already has clearly defined features and relationships. For these situations, the sheer complexity of a deep neural network can become a liability. The model might struggle to find meaningful patterns, leading to painful training times and a higher risk of overfitting—where it basically memorizes the noise in your training data instead of learning the real signal.
The Power of Simplicity with Structured Data
Algorithms like Gradient Boosting (especially XGBoost), Random Forests, and Support Vector Machines are practically built for tabular data. They are designed to work efficiently with well-defined inputs, which makes them perfect for the most common business problems.
They absolutely shine in areas like credit scoring, customer churn prediction, and sales forecasting. In these cases, the input features—like a customer's age, purchase history, or account balance—are already neatly structured. A simpler ML model can quickly pinpoint the most important predictors without the massive computational overhead that deep learning demands.
Plus, the interpretability of these models is a huge business advantage. It allows teams to understand why a certain prediction was made. Our guide on applying machine learning for fraud detection dives into real-world examples where this kind of clarity is mission-critical.
The real choice between machine learning and deep learning isn't about which is more advanced; it's about which tool is right for the job. For structured data, machine learning often delivers higher accuracy with greater speed and transparency.
Real-World Performance and Evidence
This isn’t just a theoretical hunch. Study after study shows "shallower" ML algorithms running circles around deep learning on structured datasets.
Take one recent study that analyzed vehicle traffic data from Italian tollbooths—a classic example of structured, time-series information. The gradient boosting algorithm XGBoost was more accurate than both other classical models and a deep learning Recurrent Neural Network (RNN). Researchers pointed out that for this type of stationary, structured data with clear features, simpler algorithms just adapted more effectively. You can read the full research on this performance comparison to see the detailed findings for yourself.
It really drives home a key principle our AI experts share all the time: your model choice has to be dictated by the nature of your data.
When you’re facing a problem with structured data, it's always smart to start with these proven machine learning workhorses:
- Gradient Boosting Machines (like XGBoost or LightGBM): These are often the top performers in Kaggle competitions involving tabular data for a reason. They deliver incredible accuracy and efficiency.
- Random Forests: An excellent choice for its robustness and how easy it is to implement. It gives strong results right out of the box with minimal tuning.
- Logistic Regression or SVMs: Fantastic baselines that are highly interpretable and computationally cheap. They're perfect for classification tasks where you need to understand which features are driving the outcome.
By picking the right tool for the data you actually have, you'll get better results, faster, and with far fewer resources.
Where Deep Learning Dominates With Unstructured Data
While traditional machine learning is fantastic with clean, structured data, the conversation flips entirely when we wade into the messy world of unstructured information. This is deep learning’s home turf. It’s built to handle the complex, chaotic data that makes up over 80% of the world’s information.
Think about images, audio files, and enormous blocks of text. This is the data fueling today's most impressive AI breakthroughs, and deep learning's layered architecture is uniquely designed to make sense of it all. Our expert speakers, especially those in autonomous driving and medical imaging, consistently point to this as the single biggest differentiator.
Automatic Feature Extraction
Traditional ML requires a data scientist to painstakingly engineer features by hand. Deep learning models, on the other hand, perform automatic feature extraction. A deep neural network learns its own features in a hierarchical way, straight from the raw data.
For example, give a model an image, and its first layers might learn to spot simple things like edges and colors. The next layers combine those into more complex patterns like textures and shapes, until eventually, the top layers can recognize whole objects—faces, cars, or animals. This ability to learn without human guidance is what lets deep learning conquer such incredible complexity.
Groundbreaking Applications in NLP
Natural Language Processing (NLP) is another area where deep learning completely rewrote the rules. Before deep learning, ML models really struggled to pick up on the nuance, context, and semantic relationships in human language. For complex, non-numerical info like interview transcripts or open-ended survey answers, knowing how to analyze qualitative data is crucial, and deep learning delivers the best tools for the job.
Modern deep learning models, like transformers, can actually grasp a word’s meaning based on its place in a sentence. This has led to huge leaps in:
- Language Translation: Finally capturing subtle meanings that older systems always missed.
- Sentiment Analysis: Truly understanding the emotional tone of customer reviews or social media chatter.
- Chatbots and Virtual Assistants: Powering conversations that feel far more natural and useful.
This is especially critical in specialized fields. One systematic comparison of models used to predict mental illness from clinical notes found that deep learning models were far more accurate than conventional machine learning. Why? They were better at capturing the subtle semantic differences in medical diagnoses—a task where classic methods just couldn’t keep up. You can discover more insights from this clinical text analysis study.
The core strength of deep learning is its ability to find the signal in the noise. It can process millions of data points—pixels in an image, words in a document, or soundwaves in an audio file—and identify the underlying patterns that truly matter.
This is the key takeaway. If your problem is structured and predictable, traditional machine learning is often the perfect tool. But for navigating the ambiguous, unstructured data that defines our modern world, deep learning is the engine you need.
How To Choose The Right Approach For Your Project
Alright, let's get down to the brass tacks. Moving from theory to practice is where the real work begins, and picking the right path means taking an honest look at your project’s unique needs. Our expert speakers consistently say the decision really comes down to just four things: your data's type, its volume, how explainable the results need to be, and the resources you have on hand.
The very first—and most critical—question to ask is about your data. Are you working with neat, structured information like rows in a spreadsheet, or is it a messy pile of unstructured text and images? The answer here often points you directly to the right solution.
This simple decision tree shows how your data type is the primary fork in the road.
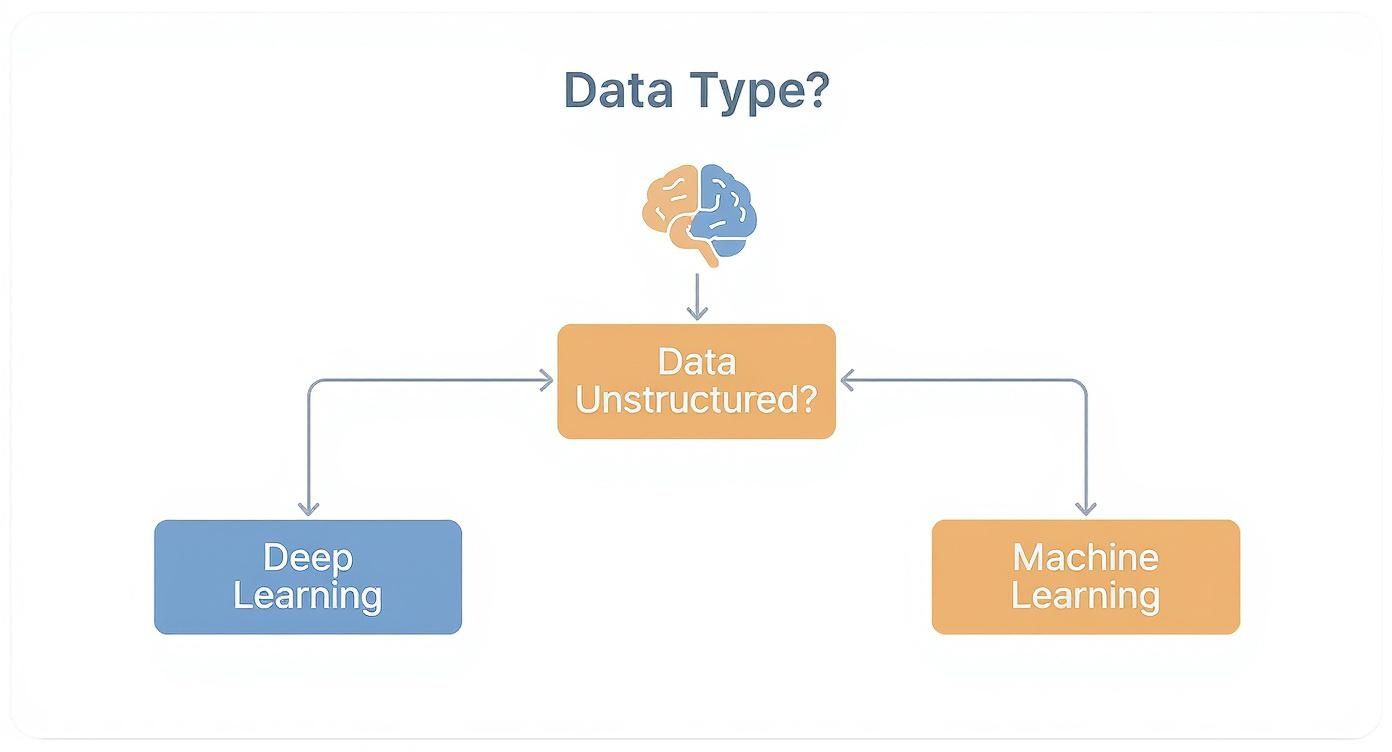
As you can see, if your data is primarily structured, traditional machine learning is almost always the best place to start. It’s simply more efficient and easier to understand.
A Framework For Deciding
Beyond that initial data question, a few other factors will help you make a smart, balanced decision. Getting these right will lead you straight to the most effective solution for your business.
- Data Volume: Are you dealing with thousands of data points or millions? Traditional ML models can deliver fantastic results with smaller, high-quality datasets. Deep learning, on the other hand, is data-hungry and needs massive amounts to perform well. Without it, you’ll see performance suffer.
- Interpretability Needs: How important is it to explain why the model made a certain prediction? ML models like logistic regression or decision trees are often called "white-box" models because their logic is transparent. Deep learning models are notoriously "black-box," which makes them a non-starter for regulated industries where you legally need to explain your decisions.
- Computational Resources: What kind of hardware and budget are you working with? Machine learning can often be trained on a standard CPU. Deep learning demands powerful GPUs, which are expensive to own or rent. This adds significant cost and complexity to your project. Getting a handle on these requirements is a crucial first step, as outlined in guides on how to implement AI successfully.
Practical Business Scenarios
Let's ground this in a couple of real-world business cases that perfectly illustrate the difference.
Scenario 1: Predicting Loan Defaults (A Classic ML Task)
A bank wants to predict if a customer will default on a loan. Their data is highly structured, with clear features like credit score, income, loan amount, and employment history.
For a problem like this, a Gradient Boosting model is the perfect fit. It's fast, incredibly accurate with tabular data, and provides feature importance scores that tell the bank exactly which factors are driving risk. That transparency is also critical for regulatory compliance.
Scenario 2: Content Moderation (A Prime DL Use Case)
A social media platform needs to automatically find and flag harmful content across millions of user-uploaded images and videos. The data is completely unstructured and comes in a massive, never-ending stream.
Here, a deep learning model—specifically a Convolutional Neural Network (CNN)—is the only way to go. It can learn to spot complex patterns directly from pixels, recognizing prohibited content with a level of accuracy that machine learning could never hope to achieve on raw visual data.
To make the choice even clearer, we've put together a quick decision guide. Use this checklist to quickly determine which approach is the best starting point for your specific project.
Decision Guide When to Use ML vs DL
| Consideration | Choose Machine Learning If... | Choose Deep Learning If... |
|---|---|---|
| Data Volume | You have a small to medium-sized dataset (hundreds to thousands of points). | You have a massive dataset (millions of points or more). |
| Data Type | Your data is structured and labeled (e.g., spreadsheets, databases). | Your data is unstructured (e.g., images, text, audio). |
| Interpretability | You need to explain the model's decisions (e.g., for regulatory compliance). | Accuracy is the top priority, and "black-box" results are acceptable. |
| Hardware | You are working with standard CPUs and have limited computational resources. | You have access to powerful GPUs and a significant budget for hardware. |
| Feature Engineering | You can manually identify and engineer the most important features. | You need the model to automatically learn features from raw data. |
| Training Time | You need to train models relatively quickly, often in minutes or hours. | You have time for long training cycles, which could take days or weeks. |
Ultimately, choosing between ML and DL isn't about which one is "better" in a vacuum. It's about matching the tool to the task at hand. By evaluating your data, resources, and business requirements against this framework, you'll be well-equipped to make a strategic choice that delivers real results.
Common Questions We Hear About ML and DL
When you're navigating the differences between machine learning and deep learning, a few key questions almost always come up. Our speakers get asked these all the time, and their answers help cut through the noise to build a practical understanding of how to apply these technologies.
Here are a few of the most frequent queries we see, along with some straightforward answers.
Can I Use Deep Learning With a Small Dataset?
This is a big one. While deep learning is famous for devouring massive datasets, you can sometimes apply it to smaller ones using a clever technique called transfer learning. It’s like giving your model a head start. You take a model that was pre-trained on a huge dataset (like a general image recognizer) and then fine-tune it using your smaller, specific set of data.
But a word of caution our experts always share: for most small, structured datasets, classic machine learning models are often the smarter choice. They deliver comparable—or even better—performance without the intense complexity and computational cost, making them a much more practical starting point.
Is Deep Learning a Type of Machine Learning?
Yes, absolutely. Deep learning isn't separate from machine learning; it's a specialized part of it. The easiest way to picture the relationship is as a set of nested dolls:
- Artificial Intelligence (AI) is the biggest doll, the broad concept of machines mimicking human intelligence.
- Machine Learning (ML) is the next doll inside. It’s a subset of AI where algorithms learn from data without being explicitly programmed for every task.
- Deep Learning (DL) is the smallest doll, a subset of ML that uses complex, multi-layered neural networks to tackle highly intricate problems.
So, all deep learning is a form of machine learning, but not all machine learning is deep learning.
The real differentiator is the architecture. Deep learning’s use of artificial neural networks, which are inspired by the human brain’s structure, allows it to process information with a level of abstraction and independence that standard machine learning models just can't match.
Which Is More Difficult to Implement?
In most cases, deep learning is the more challenging path. It demands a much deeper grasp of neural network architecture, activation functions, and optimization algorithms. You'll also be working with specialized frameworks like TensorFlow or PyTorch and will likely need serious computational muscle—usually from GPUs—to train your models in a reasonable amount of time.
Traditional machine learning models, on the other hand, are generally more straightforward to get up and running. Libraries like Scikit-learn provide friendly interfaces for a huge range of algorithms. Plus, these models can often be trained quickly on a standard computer, making them far more accessible for a wider variety of projects.
At Speak About AI, we connect you with leading experts who can demystify these complex topics for your organization. Find the perfect AI authority to inspire and educate your team by exploring our roster of world-class speakers. Book an AI keynote speaker today.